TF-IDF
Term Frequency-Inverse Document Frequency (TF-IDF) is a count-based (frequency) method used to analyze the importance of a word in a document relative to a collection of documents (corpus).
It is often used in information retrieval, text mining, and document classification.
Table of contents
Document-Term Matrix
The Document-Term Matrix (DTM) is a matrix representation of the word frequencies in a document.
Each row represents a document in a corpus, and the columns represent terms (words).
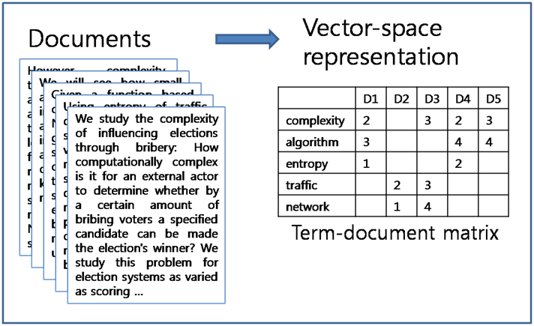
Term-Document Matrix
The transpose of the DTM is called the Term-Document Matrix (TDM).
Same thing, just that the columns represent documents and rows represent terms.
DTM Example
With corpus from Dr. Seuss:
I AM SAM
SAM I AM
I DO NOT LIKE GREEN EGGS AND HAM
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
def dtm(corpus: list[str]) -> None:
vectorizer = CountVectorizer()
vectorizer.fit(corpus)
# vectorizer.get_feature_names_out() # Get feature names
# vectorizer.vocabulary_ # Get vocabulary
dtm = vectorizer.transform(corpus).toarray()
df = pd.DataFrame(dtm, columns=vectorizer.get_feature_names_out())
print(df)
AM AND DO EGGS GREEN HAM I LIKE NOT SAM
doc0 1 0 0 0 0 0 1 0 0 1
doc1 1 0 0 0 0 0 1 0 0 1
doc2 0 1 1 1 1 1 1 1 1 0